Learning Better Rewards by Understanding Failure Over Time

Modern reinforcement learning (RL) systems have achieved impressive results in simulation and controlled benchmarks, yet they continue to struggle in real-world settings. One of the core challenges is sparse and delayed feedback: agents are often rewarded only when they succeed, and receive little to no signal when they make irreversible mistakes. As a result, learning can be slow, unstable, and brittle, especially in environments where a single wrong action can silently prevent task completion.
The Problem: Hidden Trap States in Episodic RL
In many episodic tasks, such as navigation, manipulation, or embodied control, agents may enter trap states: states from which success is no longer possible, regardless of future actions. Crucially, these states are rarely labeled or explicitly penalized by the environment. From the agent’s perspective, failure looks indistinguishable from unproductive exploration.
Existing inverse reinforcement learning (IRL) and imitation learning methods largely sidestep this issue by focusing only on successful demonstrations. While effective for mimicking expert behavior, this approach has two major drawbacks:
- It ignores the rich information contained in failed attempts.
- It discourages exploration beyond expert trajectories, limiting generalization and robustness.
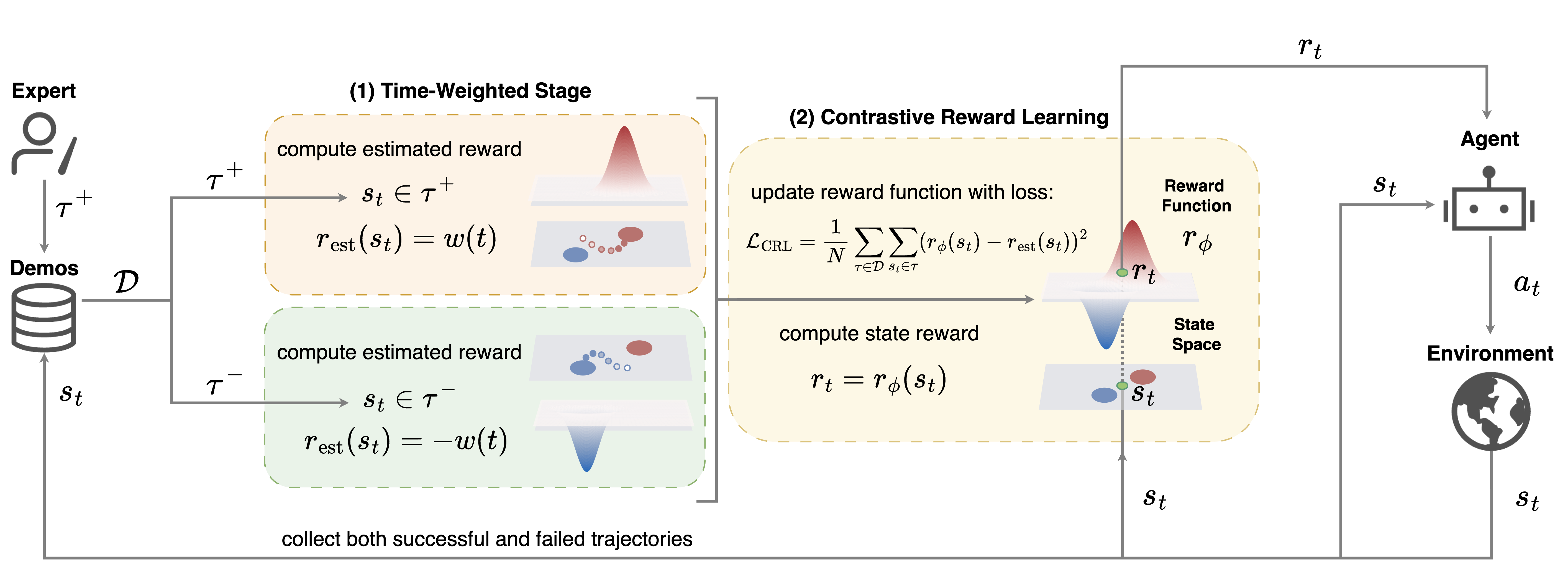
TW-CRL is a new inverse reinforcement learning framework designed to overcome these limitations by answering two key questions:
- What states lead to success or failure?
- When do those states matter most?
TW-CRL introduces two core ideas:
Idea 1: Time-Weighted Learning of Critical States
Not all states in a trajectory are equally important. In successful episodes, states closer to the end are more likely to be directly responsible for reaching the goal. In failed episodes, later states are more likely to reflect irreversible mistakes.
TW-CRL explicitly models this intuition using a time-weighted function that assigns increasing importance to states later in a trajectory. This temporal weighting allows the learned reward function to focus on decision points that actually determine outcomes, rather than treating all steps uniformly.
The result is a denser, more informative reward signal, without requiring manual reward engineering.
Idea 2: Contrastive Learning From Success and Failure
Instead of learning only from expert success, TW-CRL learns contrastively:
- States from successful demonstrations are treated as positive examples.
- States from failed demonstrations are treated as negative examples.
By combining these with time-based weighting, TW-CRL learns a reward function that approximates the difference between the probability of success and the probability of failure. This enables the agent to:
- Automatically identify unseen trap states.
- Avoid repeating failure patterns.
- Explore alternative strategies beyond imitation.
Importantly, failed demonstrations are not wasted data and actively shape the reward landscape.
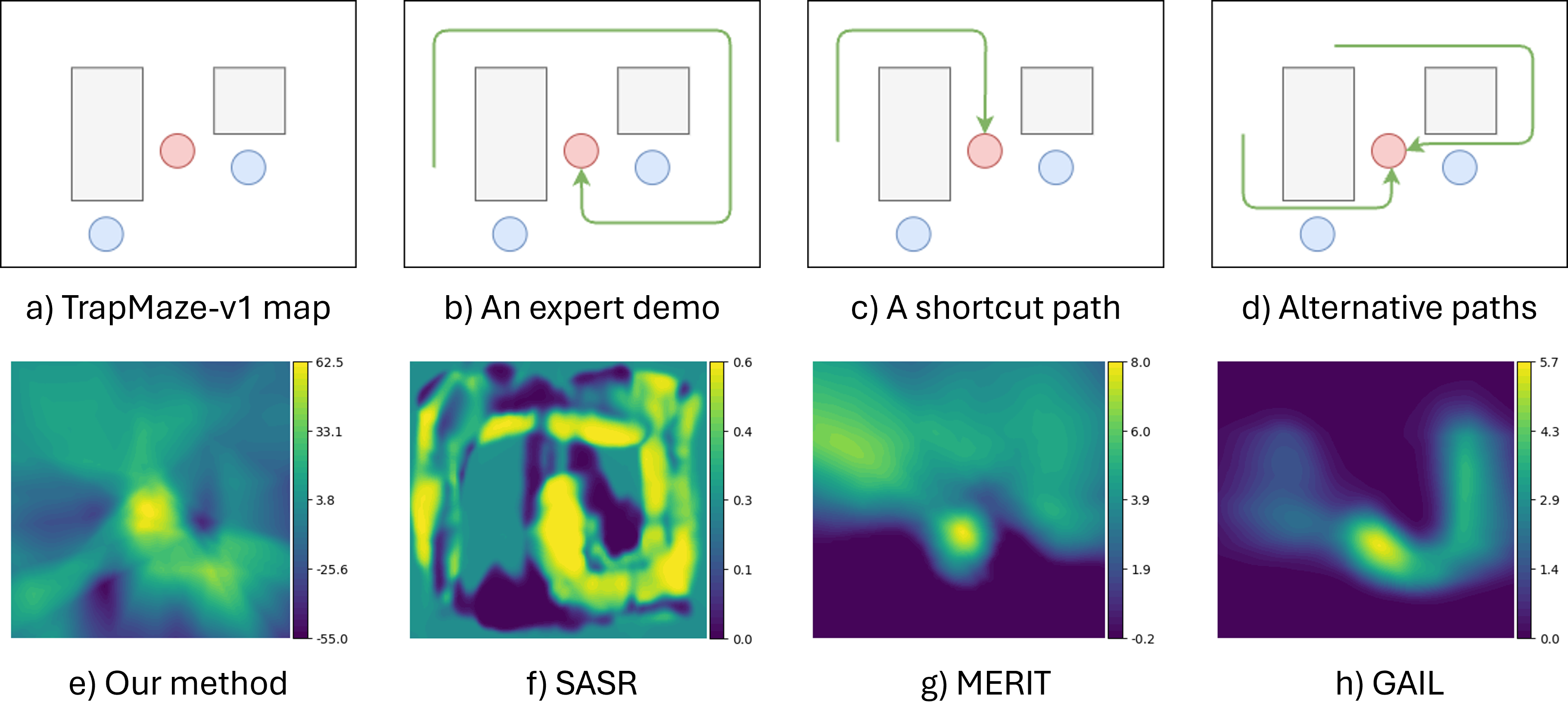
Conclusion
We evaluate TW-CRL is evaluated on eight diverse benchmarks, including maze navigation with hidden traps, continuous control tasks, and robotic manipulation environments. Across these settings, TW-CRL consistently:
- Outperforms state-of-the-art IRL and imitation learning methods
- Converges faster with lower variance
- Identifies trap states that baseline methods fail to recognize
- Discovers shortcuts and alternative strategies never shown in demonstrations
- Generalizes to unseen goal configurations
TW-CRL moves reinforcement learning beyond “learning from success” toward learning from experience as a whole. By explicitly modeling time, failure, and contrastive structure, it addresses a fundamental gap in how reward functions are learned in sparse, high-stakes environments. This makes TW-CRL particularly well-suited for a variety of agentic AI domains, including robotics, embodied AI, and safety-critical decision-making.
Publications
