TRAMBA: Practical Bone-Conduction / IMU Speech Enhancement

Vibration-based speech sensing (e.g., bone-conduction microphones and accelerometers) is inherently robust to ambient noise, but it loses high-frequency details that are critical for intelligibility and naturalness. TRAMBA restores these missing components via practical super-resolution and enhancement, enabling real-time, on-device deployment on a wearable + smartphone pipeline.
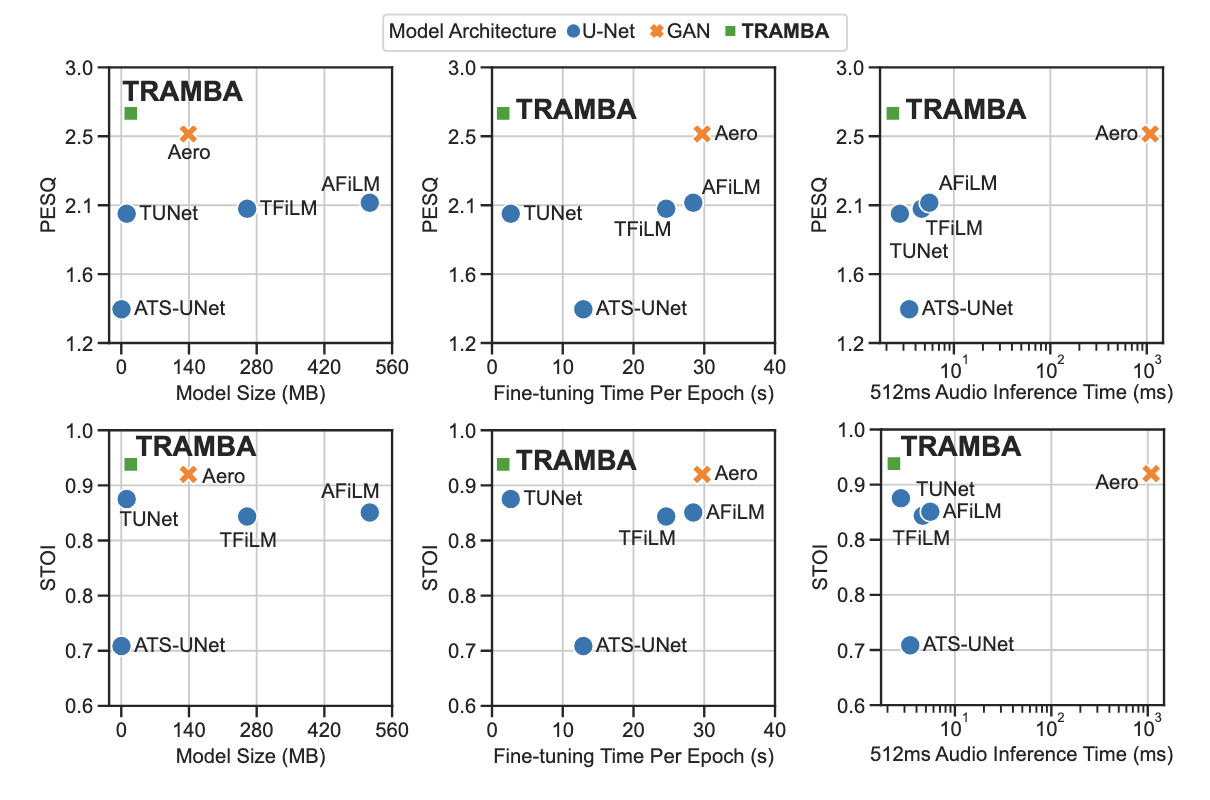
Why TRAMBA is practical
- Strong quality + fast inference on 512 ms windows.
- Small model footprint suitable for mobile deployment.
- Low-rate sensing to reduce sampling + wireless transmission cost.
- Quick user-specific fine-tuning using a small amount of paired vibration data.
Core Idea: Practical Super-Resolution from Low-Rate Vibration
Unlike over-the-air (OTA) audio, BCM/ACCEL signals already suppress many ambient noises, but they contain limited high-frequency energy. TRAMBA targets robust super-resolution from signals directly sampled at low rates (rather than “filter then decimate”), which enables savings on both:
- sampling power, and
- wireless transmission power.
Architecture
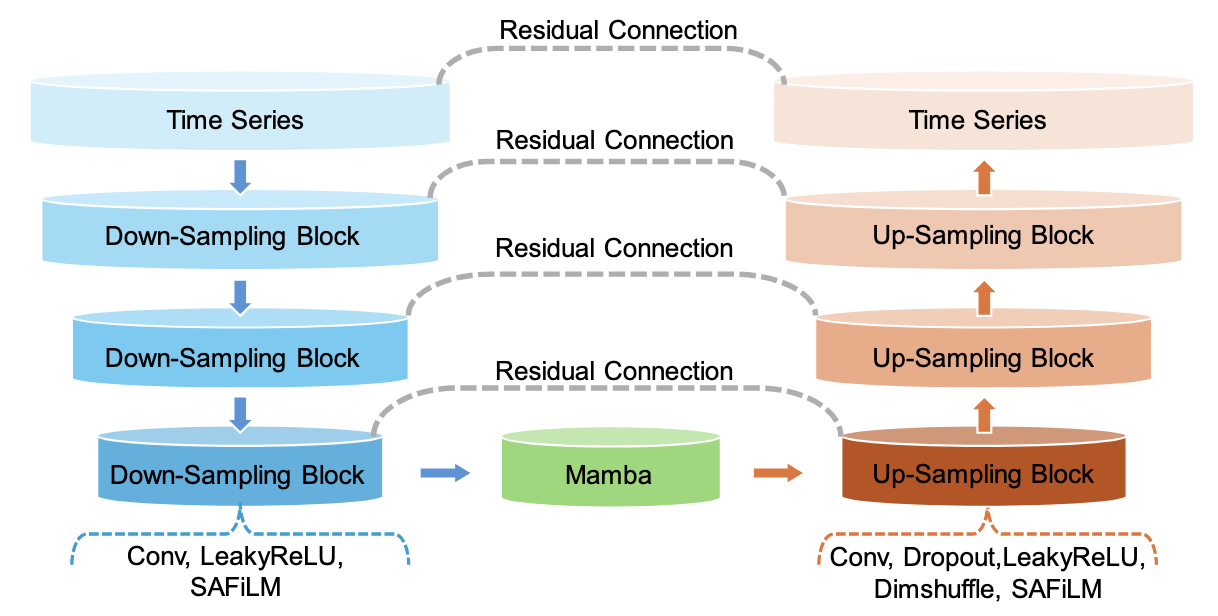
TRAMBA adopts a modified U-Net backbone with:
- self-attention in downsampling/upsampling blocks to model complex speech structure,
- a Mamba bottleneck for memory-efficient long-range modeling,
- and mobile-friendly design choices to balance quality vs. latency.
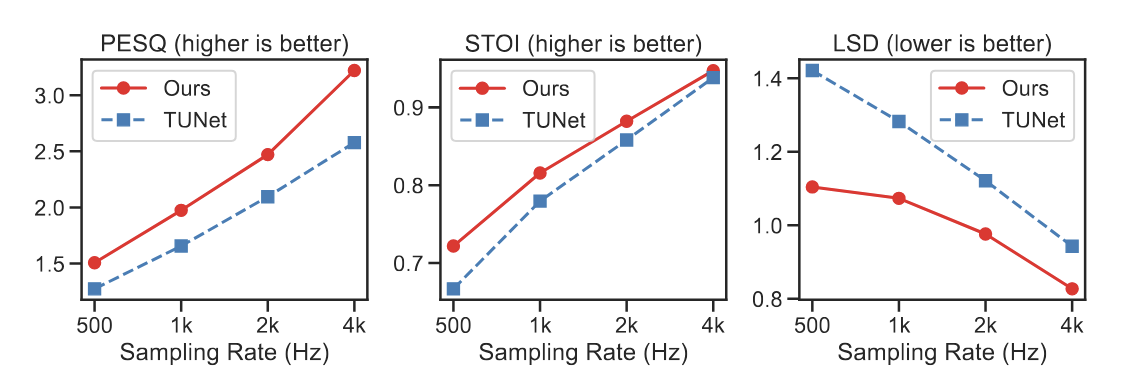
Benchmark snapshot (OTA Audio SR, 4 kHz → 16 kHz)
On the OTA audio super-resolution benchmark (512 ms window), TRAMBA achieves:
- Params: 5.2M
- Model size: 19.7 MB
- Inference time: 2.33 ms (NVIDIA L40)
- SNR / PESQ / STOI / LSD: 23.24 / 3.23 / 0.948 / 0.827
(These values match Table 1 in the paper.)
Training & Personalization (User-Specific Fine-Tuning)
TRAMBA follows a practical training pipeline: 1) Pre-train using widely available OTA audio (simulate low-rate inputs by attenuating high-frequency components). 2) Fine-tune with a small amount of paired vibration data (BCM/ACCEL ↔ OTA reference) for user-specific adaptation.
This personalization step is key for handling different users and sensor placements.
System & Prototype

TRAMBA is integrated into an end-to-end wearable/mobile pipeline:
- Wearable streams low-rate BCM/ACCEL data to a smartphone.
- Smartphone runs enhancement in real time and supports fast personalization.
Power + data-rate savings (wearable sensing + streaming)
Sampling/streaming at 4 kHz (64 kbps) consumes 3.21 mW, while streaming full-resolution 16 kHz (256 kbps) consumes 6.48 mW.
At 500 Hz (8 kbps), power drops to 2.49 mW, which corresponds to ~160% longer battery life vs. 16 kHz (6.48 / 2.49 ≈ 2.60×).
(See Table 9.)
The paper also reports that operating at 4 kHz enables 75% less transmitted data and >50% lower power compared to 16 kHz OTA streaming.
Real-time latency on phones
TRAMBA processes 512 ms windows and achieves <30 ms inference time on modern iPhones (e.g., iPhone 15 Pro: 19.584 ms; iPhone 12: 27.931 ms), enabling real-time enhancement. (See Table 10.)
Robustness: Noisy Environments & Movement
- Noise robustness: TRAMBA maintains high and consistent performance even when ambient noise becomes extremely large (paper notes cases where noise is ~10 orders of magnitude louder), while OTA denoising/source-separation can introduce distortions.
- Movement robustness: With a simple 10 Hz high-pass filter, performance under walking remains similar to standing still (Table 8).
Code and Media
Publications
-
TRAMBA: A Hybrid Transformer and Mamba Architecture for Practical Audio and Bone Conduction Speech Super Resolution and Enhancement on Mobile and Wearable Platforms.
IMWUT 2024.
https://dl.acm.org/doi/10.1145/3699757